自2019年11月底买下这台混动CRV净驰,不知不觉已经五年过去了。这台车用得怎么样?混动车值不值得买,下面就来总结一下。
一、车子缺点
这款车子最为诟病的是它的“噪音”问题,当动力电池下降到二格电时会自动启动发动机,此时嗓音非常大,即便关闭了车窗也依然能清晰听到。补充一格电之后,发动机又会自动关闭,所以驻车发动机的噪音忍一会也就过去了。
行驶中噪音也比较明显,除胎噪、风噪外主要还是发动机的噪音。看很多朋友给车子增加隔音棉、双层玻璃,我什么也没弄。
蓝牙播放音乐音质不太好,加根线改了carplay,通过carplay播放音乐,音质大为改善。
车漆、接缝等问题不说了。
二、油耗情况
我开车比较佛系,不喜欢急刹急加速,平时常开“小绿叶”,城市快速路和高速上多用“定速巡航”,城市道路20-70迈,高速路100迈左右。夏季表显油耗3.7左右,最低到3.1,冬季油耗4.3左右,最低4,车子需行驶十公里以上才能看到。曾用“小熊油耗”APP测算过,按照当前油价,每公里油费在0.35元左右。我常跑城市快速路,不大跑高速,夏季特别热时开空调,平时不开。
三、保养情况
保养都是在4S店里做的,基础保三百元左右(用券或好评送机滤),四万公里大保花了一千出头。一直用绿桶机油,前三年每五六千公里换一次,近两年每八九千公里换一次,车没出过任何问题。现在买车险还送机油或基础保养,则更省保养费。
四、省油心得
开“小绿叶”和不开“小绿叶”油耗悬殊很大,当然开“小绿叶”车子比较“肉”,佛系点开也还能接受;
多用“定速巡航”,省脚力也省油;
多用“减速”拨片来辅助刹车,十字路口前和下坡路段都要用,减速、充电、省刹车片好处多;
动力电池电量过半时主动切换为“EV”驱动;
下快速路后,车机电脑会沿用快速路上的油驱模式,踩油门时发动机会主动介入,这时要松开油门,发动机也会停机,确认三次后,车机电脑会切换为电驱模式(个人认为的,不确定);
车越快越费油,越慢越省油,不要猛踩油门,不要让车机电脑认为你在爬大坡或急加速。
五、值不值得买?
一辆这么大的车,不到五个油,值不值得?各有各的看法,我觉得很不错了!
动力电池会不会衰减?首先说动力电池是辅助发动机工作的,目的是让发动机工作在最佳工况下。系统对电池浅充浅放,五年下来丝毫感觉不到电池的衰减问题。曾测试让电池处在低电量下(车慢慢走),发动机会不停启动给电池充电,当达到一定次数后,系统会暂停使用EV模式并持续给电池充到80%的电(电量差一小段满格),可见系统对电池的保护力度。
总结:
从油耗、保养以及行车体验来看,我认为混动版CRV是辆难得的家用好车,除了噪音大点,开“小绿叶”后“肉”一点,几乎没有明显的“短板”。行驶中油电动力切换非常平滑,根本感觉不到任何顿挫,体验非常好!
附:最近两年“小熊油耗”年度用车报告
阅读全文…
妻对我说,她最近看到一个短视频讲的是一位清华大学的毕业生在流浪。
我说,这有什么奇怪的,我也看到一个清华的女生在云南大理隐居;一个北大地质系的跑到北美种菜;还有一个人大的艺术系的单人单车长期旅行。如果用中国传统的观念来看,父母辛苦多年把孩子送进了名牌大学,本该出人头地、光宗耀祖、大展宏图是不是?
妻说,不可理解。
我说,你还记得2019年网上爆红的流浪公务员沈巍吗?好好的工作不做,每天去捡垃圾。
妻说,看他出口成章,思维敏捷,本该有大好前程,一样让人费解。
是的,社会上出现的一些人一些事看似不可能,却实实在在地发生着。思前想后,我得出一个肤浅的结论:世俗不再是禁锢人们思想的枷锁,每个人都有选择自己生活的权利!
方才提到的那些人,生活中或许存在着不为人知的困难,使得他们不得不这样生活,而我们也没看到他们生活得很痛苦,相反他们似乎还乐在其中。反过来我想问一下,我们为什么一定要沿着前人的轨迹来生活呢?
“鞋子合不合适,只有脚知道”,每个人都可以选择适合自己的生活。而对于我,生活似乎也到了需要改变一下的地步了。
我从事的IT行业严格来说是年轻人的行业,技术更迭比较快,需要不断地学习充电。我早已步入中年,日常琐事多精力分散,学习新知识很吃力。而且学过的东西不能立马用上,导致学了忘,忘了再学,陷入了一个怪圈。有时候反过来想,即便是学好了又有多大胜算能和年轻人去比拼呢?我在IT这条路上又能走多久?我自己都没有信心了!
今年以来,我一直在考虑转行问题。转行对我来说意味着另一种生活的开始,也是我下半生的新开始。我该怎样转?
我对计算机比较熟悉,各种电脑软硬件故障都可以处理(板卡芯片级维修不行,没这条件);
我懂网站建设,从服务器运维到网页设计再到后端程序开发,都比较熟练;
我也懂一些编程,独立开发过网站CMS系统、爬虫、图片库管理系统等。
这些技能能不能维持我的生活?能不能找出一项来重点发展?
未来两年,持续探索!
我和爱人结婚的那一年,爱人在院子里种了一株珊瑚樱,小小的盆,小小的苗,弱不经风。
它静静地呆在院子的角落里,一点都不起眼。爱人很忙,偶尔给它浇点水,就没有其它照顾了。
到了秋天,院子里的石榴树、无花果树都纷纷落叶的时候,这株小小的珊瑚樱,叶片也早已落尽,露出了两根光秃秃的枝杈,毫无生气。
记的那年是个暖冬,没怎么结冰。我们一家人忙忙碌碌的,甚至都忘了它的存在,自然也没把它“请”进屋里。
冬去春来,院子里的树木都在吐芽的时候,爱人惊喜地发现珊瑚樱还活着,它已经长出两片小叶了。爱人给它换了一个大点的花盆,加了一点点花肥。
珊瑚樱在一天天地长大,爱人除了偶尔浇点水,就没有其它照顾了。
进入六月,它开出了几朵白色的小花。花谢之后,结出了几颗绿色的小圆果,很小,不仔细都看不出来。
院子里的树长得枝繁叶茂,将大半个院子都笼罩在阴凉之下。但凡进到院子里来的人无不被这满树的石榴、柿子、无花果所吸引,没人会注意到角落里的珊瑚樱。它的叶片也绿得发黑,果子长大了许多,有几个有点想变黄。
到了七月中旬,珊瑚樱的果子大多由黄变红,突显在一片浓绿之上,刹时引人眼。进出院子里的人也都注意到它了,邻家的小孩子趁我们不注意,偷偷地摘了几个跑了,让爱人心痛不已。
第二年的秋天,珊瑚樱叶片落尽,枝头上的红果依然傲挺着,给这萧杀的晚秋带来一抹喜色。 阅读全文…
因工作需要,要将包含某些“关键词”的网页文件从磁盘中查找出来。在网上找了很久都没有找到顺手的工具,所以就动手写了一个。“独乐乐不如众乐乐”,分享给大家。Python语言初级,见笑了!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| import os,re
#获取当前目录下所有文件名及目录名
def pri_all_file(dir):
names = os.listdir(dir)
li = []
extension = ['.shtml','.html','.htm'] #定义要查找的文件类型
for name in names:
full_name = os.path.join(dir,name) #拼接成完整路径
if os.path.isdir(full_name):
#li.append(full_name)
li.extend(pri_all_file(full_name)) #递归遍历子目录下文件及目录,并一次性加入原列表中
else:
#print(full_name)
if os.path.splitext(name)[-1] in extension: #取文件扩展名进行比较
li.append(full_name)
return li
#将列表中的内容一行行写入文件
def write_result_file(result):
ls = os.linesep #行分隔符
filename = "result.txt" #保存结果的文件,在.py文件所在的目录中
try:
fobj = open(filename,'w')
except IOError as e:
print("file open error:",e)
else:
fobj.writelines('%s%s' % (txt,ls) for txt in result)
fobj.close()
#程序主体
if __name__ == "__main__":
dir_name = '/wwwroot' #定义要查找的文件夹
keyword = ['张三' ,'李四'] #定义要查找的关键词
findfilelist = [] #找到的文件列表
filelist = pri_all_file(dir_name)
for filepath in filelist:
f = open(filepath, encoding='utf-8')
try:
t = f.read()
except:
f = open(filepath, encoding='gbk', errors='ignore')
t = f.read()
f.close()
pattern = re.compile('<body[\s\S]*?</body>', re.IGNORECASE) #定义一个取出body内容的正则表达式,忽略大小写
result = pattern.findall(t) #进行匹配,找到所有满足条件的
content = "".join(result) #列表转化为字符串
if len(content) != 0:
for k in keyword: #循环关键词
if content.find(k) != -1:
print('\r[%s] %s' % (k,filepath))
findfilelist.append('['+k + '] ' + filepath) #找到则输出文件地址
# if os.path.isfile(filepath): #判断是否是为文件(文件是否存在)
# os.rename(filepath, filepath + '_bak') #修改文件名
print('\r%s' % (filepath), end = '')
write_result_file(findfilelist) #将查找结果写入result.txt文件中 |
import os,re
#获取当前目录下所有文件名及目录名
def pri_all_file(dir):
names = os.listdir(dir)
li = []
extension = ['.shtml','.html','.htm'] #定义要查找的文件类型
for name in names:
full_name = os.path.join(dir,name) #拼接成完整路径
if os.path.isdir(full_name):
#li.append(full_name)
li.extend(pri_all_file(full_name)) #递归遍历子目录下文件及目录,并一次性加入原列表中
else:
#print(full_name)
if os.path.splitext(name)[-1] in extension: #取文件扩展名进行比较
li.append(full_name)
return li
#将列表中的内容一行行写入文件
def write_result_file(result):
ls = os.linesep #行分隔符
filename = "result.txt" #保存结果的文件,在.py文件所在的目录中
try:
fobj = open(filename,'w')
except IOError as e:
print("file open error:",e)
else:
fobj.writelines('%s%s' % (txt,ls) for txt in result)
fobj.close()
#程序主体
if __name__ == "__main__":
dir_name = '/wwwroot' #定义要查找的文件夹
keyword = ['张三' ,'李四'] #定义要查找的关键词
findfilelist = [] #找到的文件列表
filelist = pri_all_file(dir_name)
for filepath in filelist:
f = open(filepath, encoding='utf-8')
try:
t = f.read()
except:
f = open(filepath, encoding='gbk', errors='ignore')
t = f.read()
f.close()
pattern = re.compile('<body[\s\S]*?</body>', re.IGNORECASE) #定义一个取出body内容的正则表达式,忽略大小写
result = pattern.findall(t) #进行匹配,找到所有满足条件的
content = "".join(result) #列表转化为字符串
if len(content) != 0:
for k in keyword: #循环关键词
if content.find(k) != -1:
print('\r[%s] %s' % (k,filepath))
findfilelist.append('['+k + '] ' + filepath) #找到则输出文件地址
# if os.path.isfile(filepath): #判断是否是为文件(文件是否存在)
# os.rename(filepath, filepath + '_bak') #修改文件名
print('\r%s' % (filepath), end = '')
write_result_file(findfilelist) #将查找结果写入result.txt文件中
《中国新闻网》客户端分享出来的文章,用PHP常规采集获取不到新闻内容。经过一番探索,发现了其中的“秘密”。现将过程分享如下。
打开这个网址:https://m.chinanews.com/wap/detail/zw/gn/2022/02-23/9683825.shtml 查看网页源码,很显然新闻内容都是通过JS加载进来的。
在浏览器中按F12,打开“开发者工具”,切换到“Network”面板,按F5刷新页面,结果出来了。点击“Fetch/XHR”子面板,第二条就是获取内容的链接。

我们在该链接上点鼠标右键选择“Open in new tab”却发现打开的网页没有任何内容。看来是在“Request Headers”上做了“手脚”。
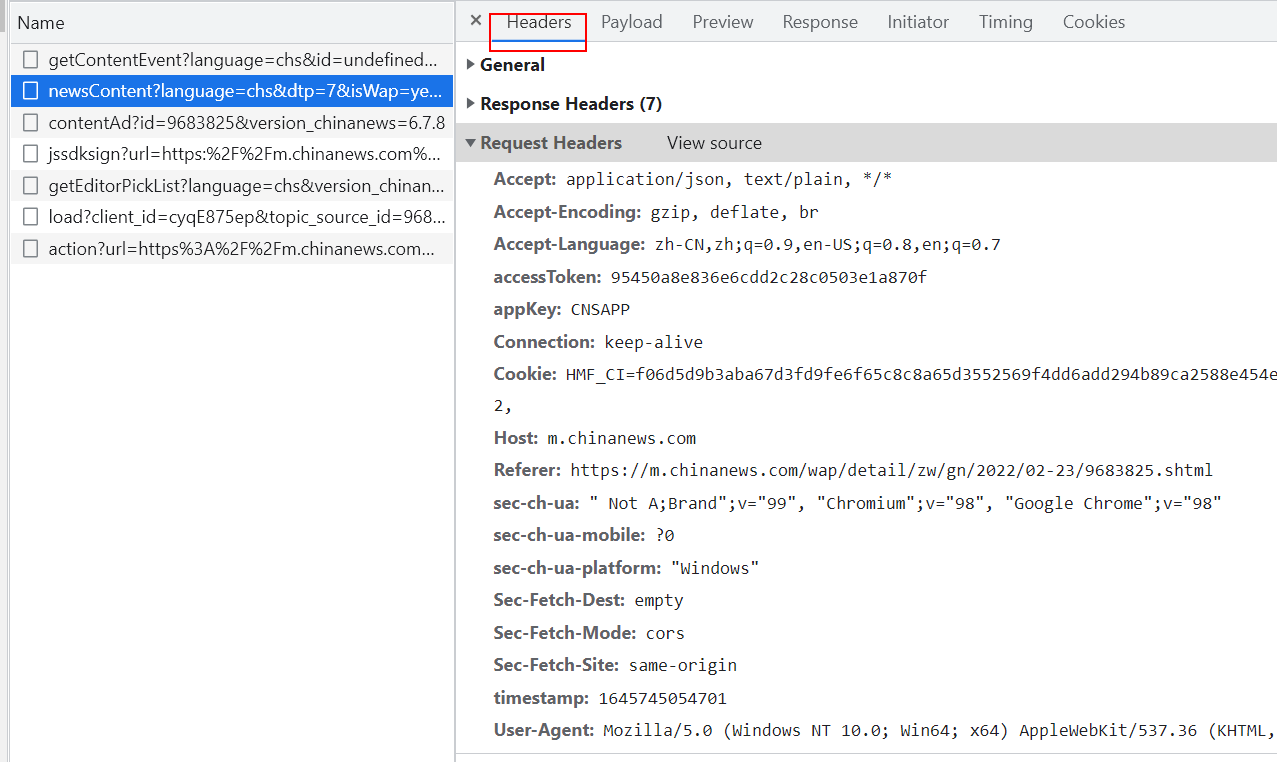
通过几次比较“Request Headers”。发现只有“accessToken”和“timestamp”有变化。 阅读全文…